What Nielsen’s “Plot Holes in AI” Study Means for the Future of Archive Monetization

AI is here to stay, but if not used properly, it can be an expensive form of cost reduction.
06.22.2026
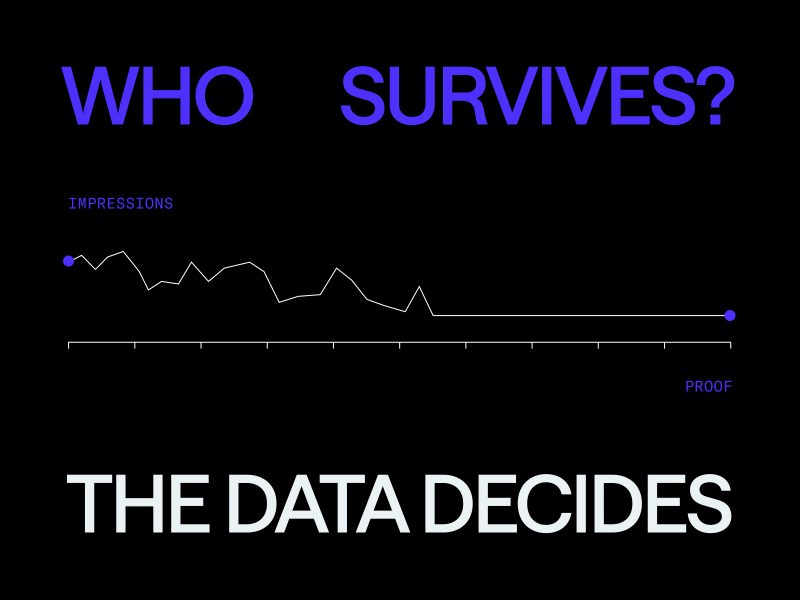
If you’re counting on AI and automation to help viewers rediscover your library, a new study from Gracenote, a Nielsen company, shows some hesitancy may be required. Researchers ran 2,600 of the top movies and TV titles across 13 countries through an ungrounded large language model – essentially an AI working from memory alone, with no live data to check itself against, which is how most of the tools made available to Media companies function. Gracenote describes the resulting errors as “plausible-sounding but false information,” and the numbers show us how essential humans really are.
Recency is the obvious issue, but Content Similarity is the silent killer
Ungrounded Large Language Models (LLMs) get shakier the newer the content. For U.S. titles, the model hallucinated 58% of its answers about 2026 releases, 30% for 2025, and 12% for anything older. That makes sense; these models are trained up to a cutoff date that, as Gracenote notes, often lags the real world by six months or more. New content is simply a blind spot.
For Media companies looking to monetize old content, this is borderline a nonissue – or at least only an issue 12% of the time, compared to 58%. The real concern is what this study showed regarding Content Similarity, which is the real killer, especially when it comes to extensive TV libraries.
The study asked about the 2025 thriller Heel, a film about a couple who kidnap a teenager. The AI nailed the title and the year, then confidently described a wrestling drama, listed the wrong cast, and tagged the wrong genre. It had quietly swapped in details from Heels, the Starz series that aired from 2021 to 2023.
The model didn’t just get one title flat-out wrong – it mixed and matched, pulling the correct year from one title and the wrong plot from another, all inside a single answer. Across the study, the LLM hallucinated 100% of the metadata for 506 titles, nearly one in five, while nearly 50% of the Ungrounded LLMs scores were of low or zero quality, – meaning over a quarter of responses were only partially correct. When errors are scattered across fields like that, a quick spot-check won’t save you because much of it looks plausible.
Why this hits archive monetization the hardest
If you monetize a deep, older catalog – exactly the kind with sequels, remakes, and similar formats across seasons – similarity errors are going to be your daily reality for a long time. To an ungrounded model, a 2008 Trucker, about a long-haul truck driver and her 11 year old son, and a 2024 Trucker, about a revenge rampage of a trucker who lost his family, are interchangeable.
For FAST channels, that means automated curation can’t be trusted to build lineups on its own. Without deep, descriptive, human-verified tagging on every title and episode, you’ll get mismatched scheduling and viewers tuning out. For compilation strategies on YouTube, Meta, and similar platforms, the stakes are the same; AI-assembled compilations will fold in the wrong footage, repeat segments, and crater watch time – the one metric those platforms actually pay you on.
The takeaway isn’t “avoid AI.” It’s that AI is only as good as the data grounding it – and that data is not yet good enough to make human intervention obsolete. AI tools only start to meet the bare minimum once they can access extensive, rich, accurate, human-maintained metadata – but for content owners with massive libraries and a high level of content similarity, any feasible amount of metadata still may not be enough.
Sources: gracenote.com